How Does the Apple Ads Auction Actually Work?

Apple’s public documentation tells advertisers that Search Results ads are determined by a mix of keyword targeting, relevance, and bid, that broad match expands to close variants, misspellings, synonyms, related searches, and phrases containing the keyword, and that Search Match automatically matches ads using app metadata, similar apps, and other search data. Apple also explicitly recommends using more aggressive bids for important exact match keywords, strong bids for broad match, and more moderate bids for Search Match discovery traffic.
That sounds straightforward, but it leaves the central operational question unanswered:
How much does semantic relevance actually matter once an app is in the auction?
To answer that, I analysed a real UK Apple Search Ads auction dataset built throughout this project from APPlyzer: 132 keywords and 627 keyword–app auction observations, matched to app metadata and rescored using a more semantic LLM relevance model. The goal of that model was not to measure keyword overlap, but to answer a more human question:
Would a user searching for this term reasonably expect this app to solve their need?
That produced a much clearer view of how Apple Ads likely works in practice.
1. The dataset and what was measured
For each keyword in the auction matrix, I had up to five auction positions:
ASA #1
ASA #2
ASA #3
ASA #4
ASA #5
For each app ID in those positions, I attached:
app title
subtitle
description
category
Then I applied an LLM-style semantic relevance score from 0 to 100.
From there, I could compare:
The semantic order of apps for a keyword
The actual Apple Search Ads auction order
I also inferred a likely targeting type for each app/keyword combo:
Exact: very high semantic relevance
Broad: moderate semantic relevance
Search Match: weak semantic relevance / loose expansion
This is not Apple-exposed ground truth, but It is the best observable hypothesis from the data I now had!
2. The headline result
The data says Apple Ads is not a pure relevance auction.
The most important statistics were:
Exact relevance order matched the auction order on only 7.6% of keywords
The most relevant app was actually #1 in only 43.9% of keywords
That is enough to say:
semantic relevance matters
but it is not the dominant factor setting the final order
If relevance were the main ranking driver, the most relevant app would win much more often than 44%.
Supporting charts
The charts in the carousel below support the analysis:
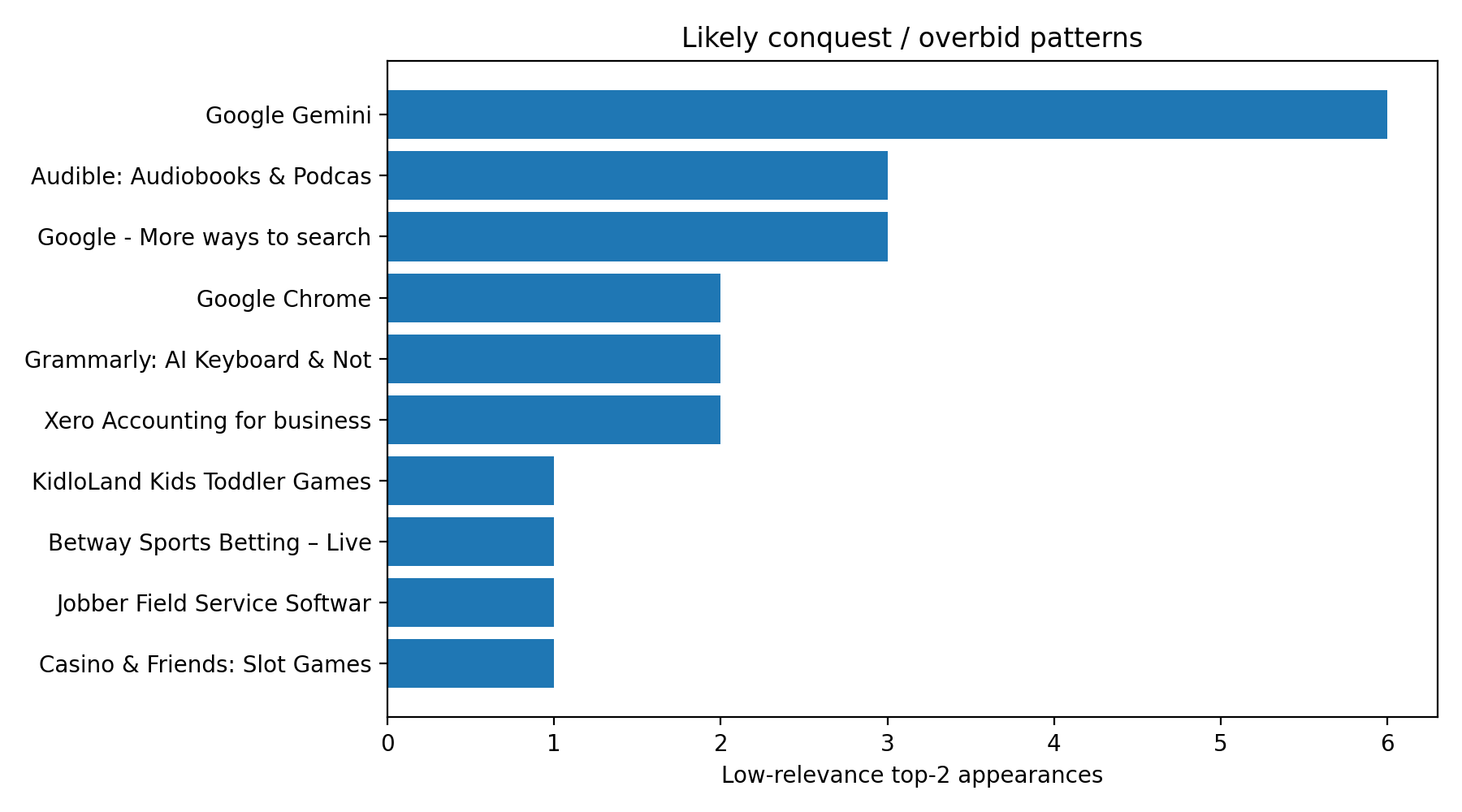
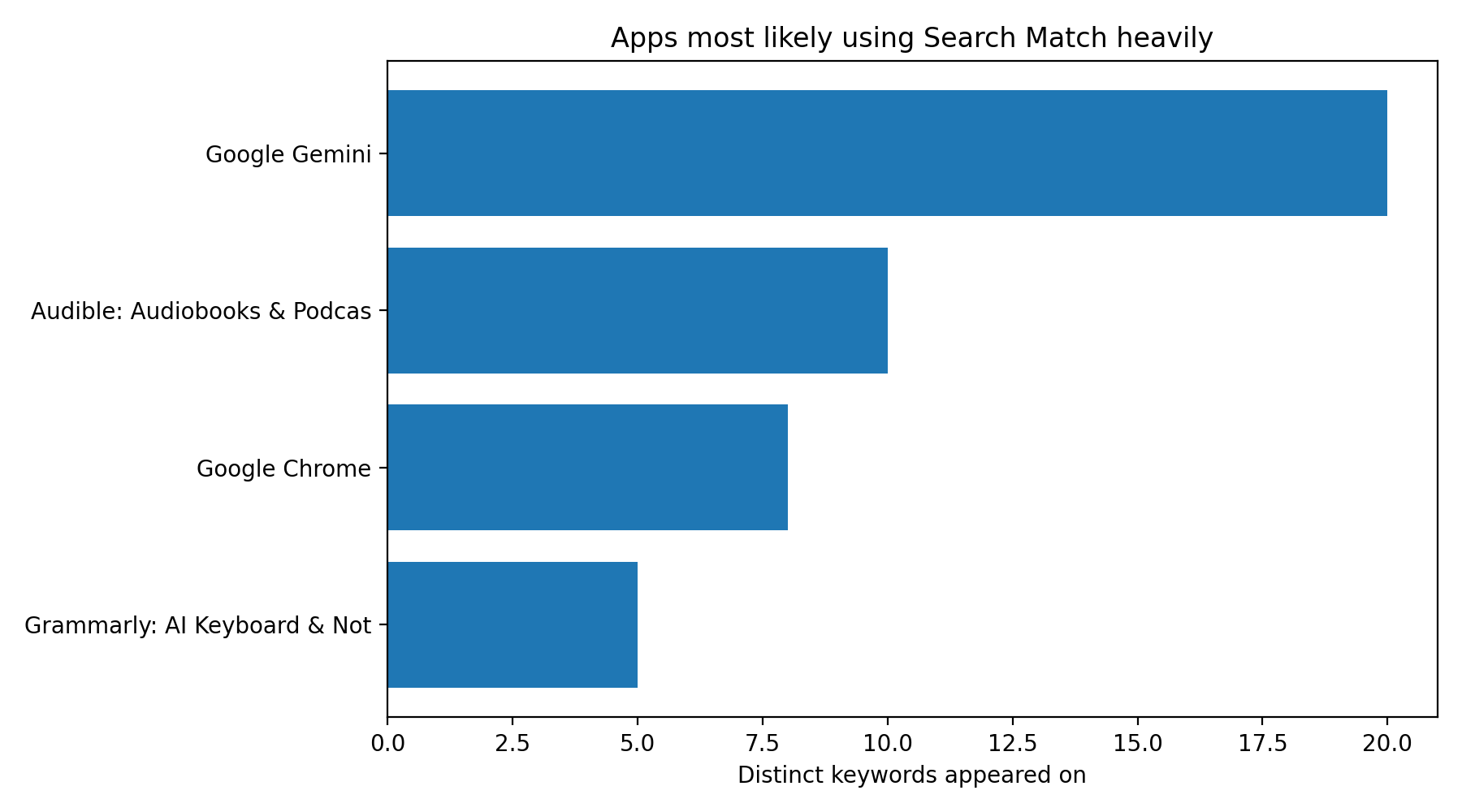

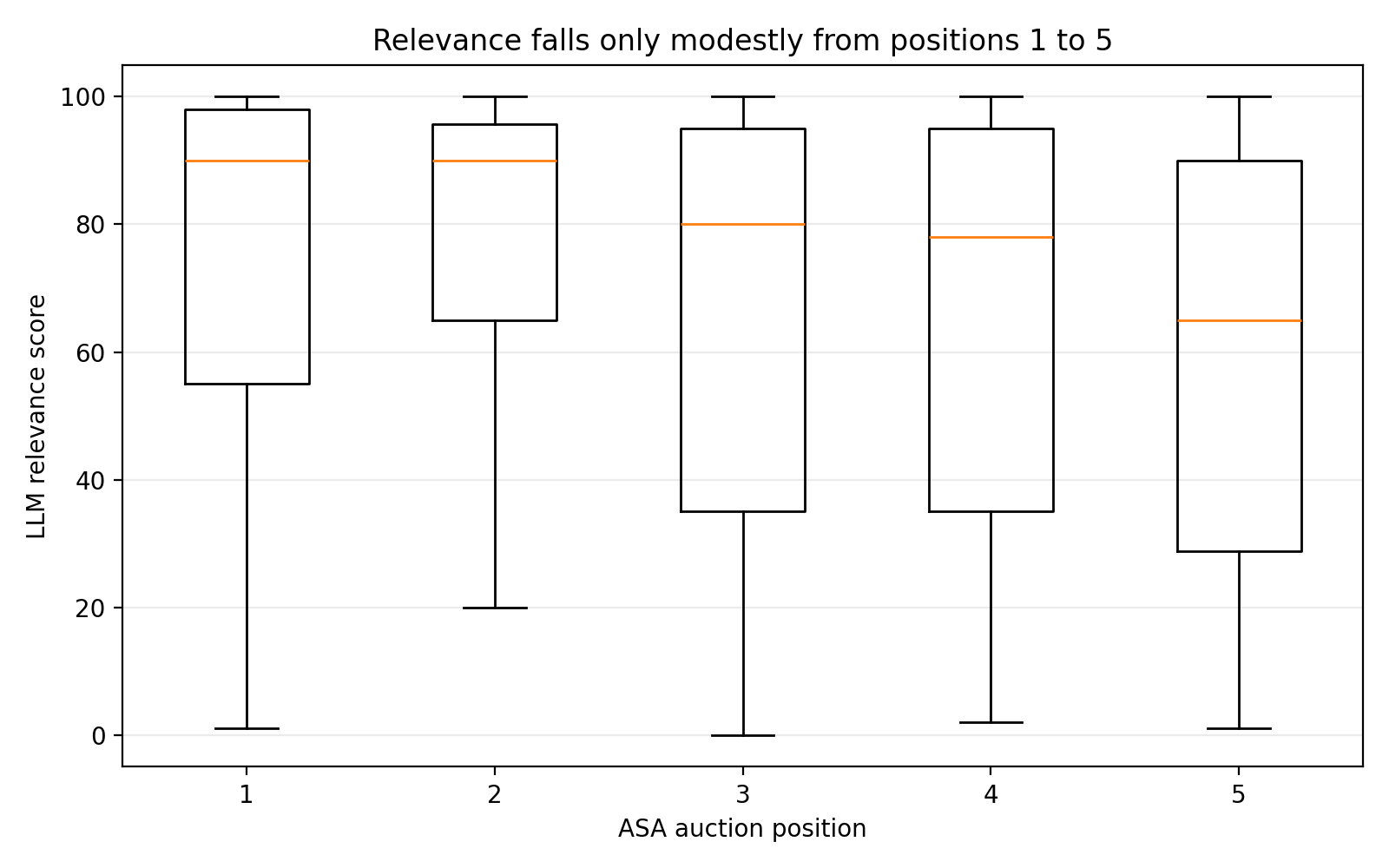
The most striking of these is the relevance-by-position chart: the distributions for positions 1–5 overlap heavily. In fact, the average relevance at position #2 is slightly higher than at #1 in this dataset, which is a strong signal that bid and expected performance are reshuffling the order after eligibility.
3. What Apple tells us publicly
Apple’s docs are actually directionally consistent with the pattern in the data.
Apple says that:
Most traffic should ideally come from exact match, while broad match and Search Match are discovery tools and should generally use more moderate bids
Apple recommends using the Search Terms tab and negative keywords to refine and cut off irrelevant traffic
That implies a three-stage system:
candidate generation via exact, broad, or Search Match
eligibility gating
auction ranking
The data strongly suggests that those three stages do not apply the same relevance threshold.

4. A more realistic model of the Apple Ads auction
The best explanation of the dataset is:
Exact match → strong semantic relevance gate
Broad match → relaxed semantic relevance gate
Search Match → very weak semantic gate plus behavioural / similarity signals
Then, once an app clears the gate:
Bid and predicted performance do most of the real ordering work
That fits Apple’s public documentation, which repeatedly frames Search Match as a discovery tool and recommends more moderate bidding there, while reserving more aggressive bids for exact match terms.
A simple mental model is:
Auction rank ≈ bid × predicted engagement × relevance
Apple does not publish that exact formula, but the behaviour of the dataset is very consistent with it.
5. Worked examples from the real auction stack
Example 1: a clean exact-intent market → “vpn”
This is what a healthy, relevance-led auction looks like.

This is exactly what advertisers imagine Apple Search Ads should look like. The keyword is explicit, the intent is narrow, the category is mature, and the whole stack is semantically on-topic.
This is also why Apple recommends exact match as the primary source of efficient traffic. In a market like this, exact is doing what it is supposed to do.
Example 2: a classic overbid / Search Match distortion → “flight track
Now compare that with this:
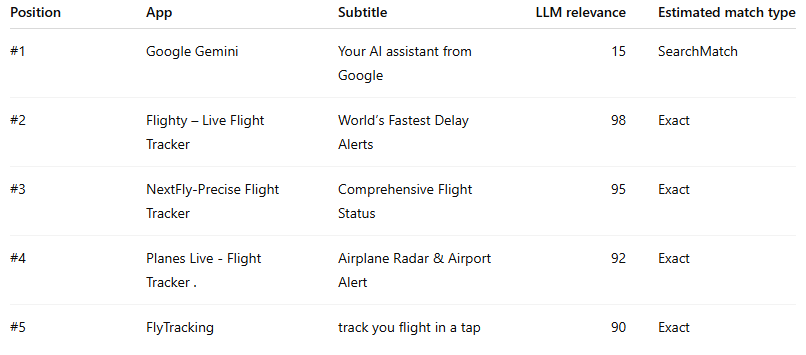
This is one of the clearest examples in the dataset of the auction not being sorted primarily by semantic fit.
If the auction were relevance-led, the top four positions would almost certainly be some permutation of the four actual flight-tracking apps. Instead, Gemini takes slot #1 despite being the least relevant app in the stack by a huge margin.
This is the kind of result that makes sense only if:
Search Match or broad expansion surfaced the candidate
the relevance gate was permissive enough to let it through
bid and/or expected performance pushed it to the top
Example 3: the “how is this even here?” case → “pdf scanner”
This keyword is even more extreme.
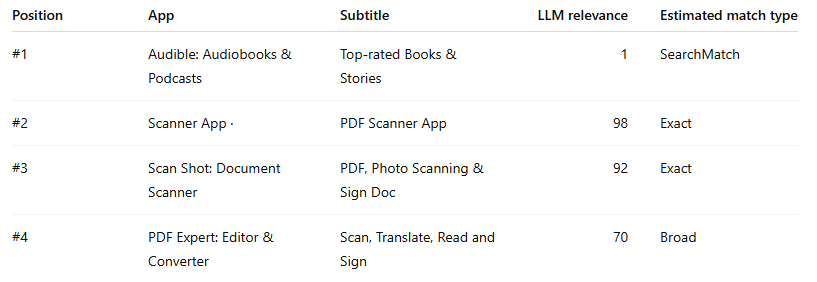
This is one of the strongest pieces of evidence in the dataset that Search Match can be extremely permissive.
Audible is not a scanner. It is not a document capture tool. It is not even weakly in the same function family in a practical App Store sense. And yet it is #1.
This is exactly why Apple tells advertisers to monitor the Search Terms tab and actively add negative keywords for searches that do not apply.
Example 4: a missed opportunity / probable underbid → “ai photo enhancer”
This is the reverse pattern: a highly relevant app losing despite being one of the best semantic fits.
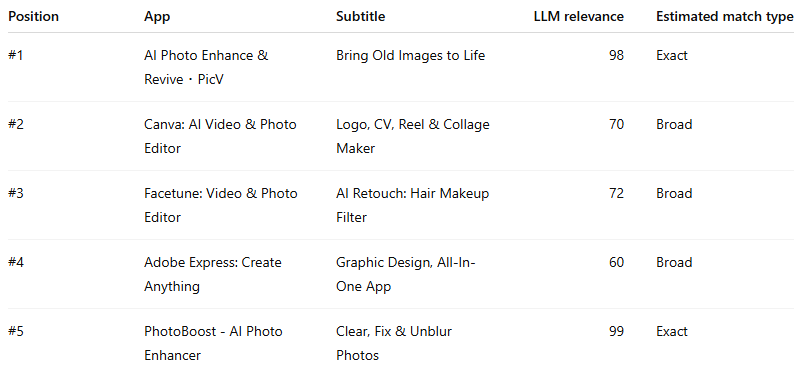
This stack is fascinating because the #5 app is actually the highest-scoring semantic match in the whole set. If you are the manager of PhotoBoost, this is not a metadata problem. It is a commercial problem.
The app looks undervalued in the auction, not irrelevant.
Those are the keywords campaign managers should obsess over, because they often point to genuine upside: increasing bid, isolating the term in exact, or protecting it from discovery leakage could all plausibly improve position.
Example 5: a Search Match-dominated market → “digital catalog”
This is what a keyword looks like when the stack is almost entirely detached from semantic fit.
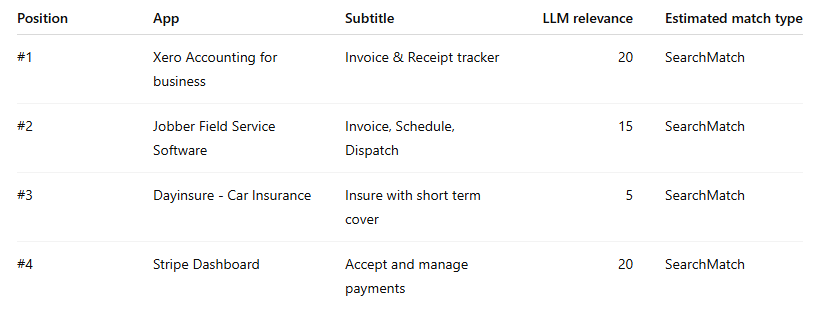
This keyword is one of the strongest examples of a market dominated by Search Match-style loose expansion. There is no clean exact leader because the stack itself appears to have drifted away from the core intent of the keyword.
In a market like this, using exact and aggressively sculpting negatives is usually the only route back to quality traffic. Apple’s own campaign structure guidance effectively points in that direction: use discovery to find terms, then move proven search terms into exact and negate them back out of discovery.
Example 6: the underbid paradox → “translator”
This stack is a great reminder that relevance alone does not buy the top slot.
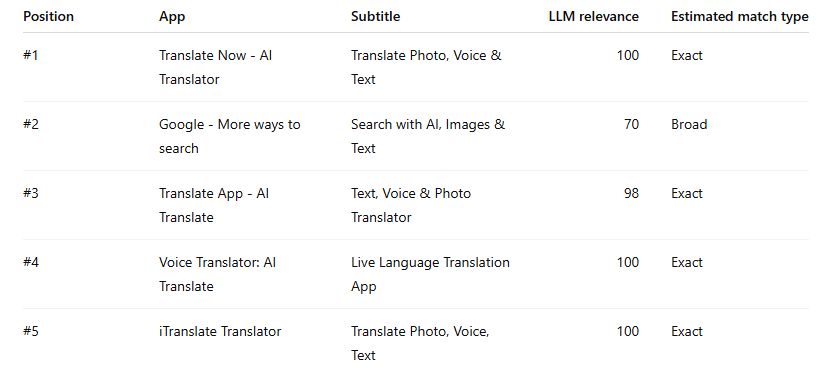
The striking point is not #1 - that’s perfectly reasonable. The striking point is that iTranslate, a direct semantic match, is sitting in #5 despite also scoring 100.
This is what underbidding or auction underperformance looks like. The keyword is relevant, the app is relevant, but the auction slot says the commercial strength is not there.
What the match-type mix looks like in aggregate
Using the relevance thresholds:
75+ → Exact
35–74 → Broad
Below 35 → SearchMatch
the auction stack breaks down like this:
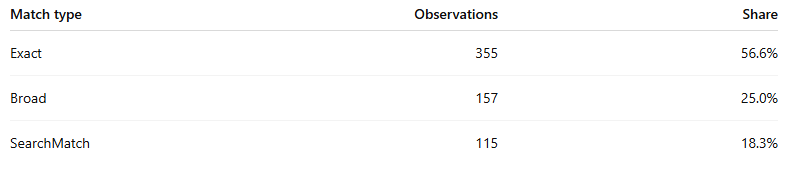
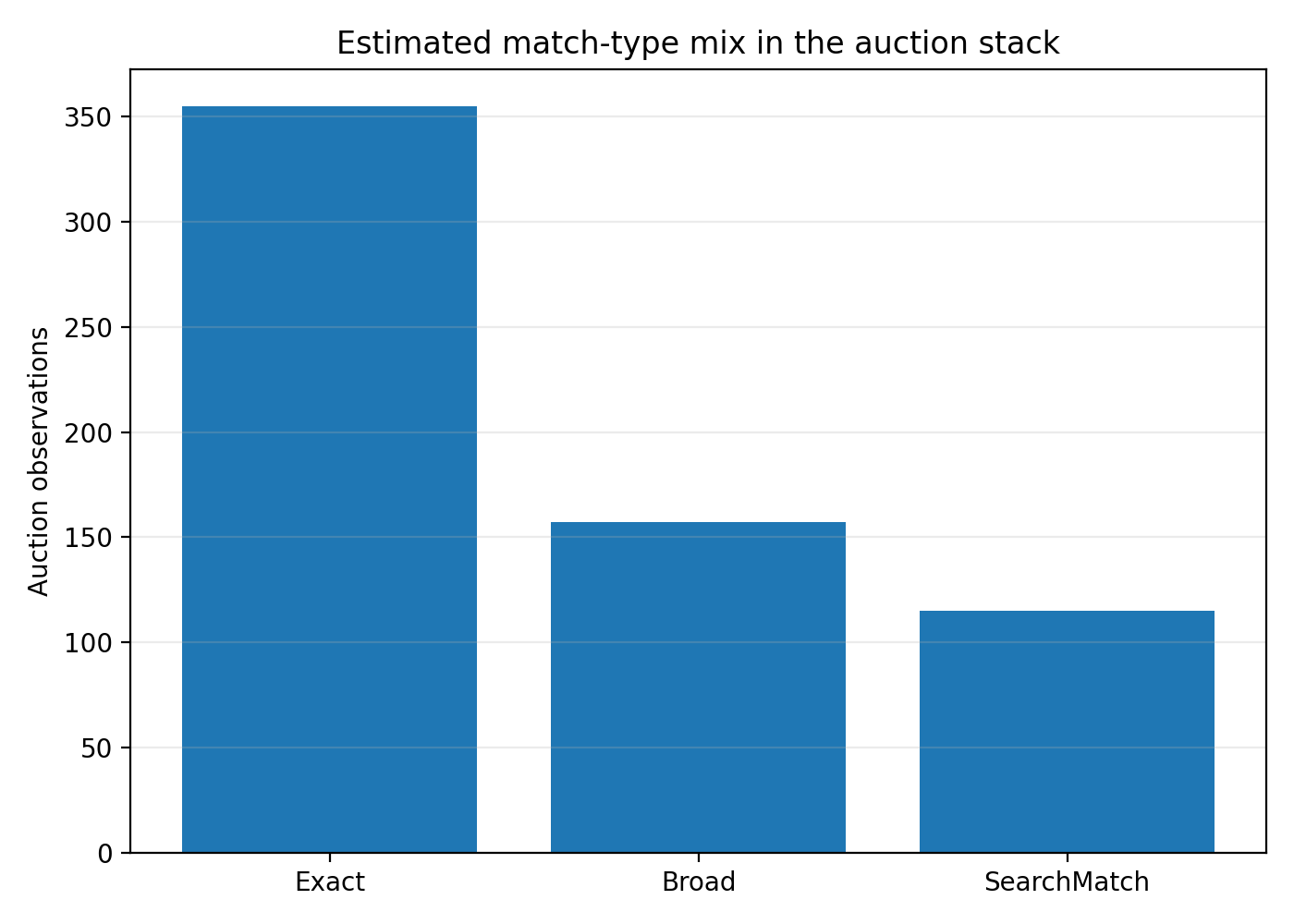
That is an important result. The auction is not mostly junk. Most ads in the stack still look strongly relevant. But nearly one in five observations look like Search Match-style loose expansion, which is enough to create major noise, distort CPCs, and generate very odd competitive sets.
What bid pressure and missed opportunity look like
To make this actionable, I built a simple Bid Pressure Index:
Bid Pressure Index = Relevance Rank − Auction Position
Positive values mean an app is winning higher than its relevance rank suggests. Negative values mean an app is more relevant than its position implies.
That gives you two strategic clusters.
Cluster 1 - Likely overbidding / conquest cases
These are apps that repeatedly appear high despite modest or weak relevance.
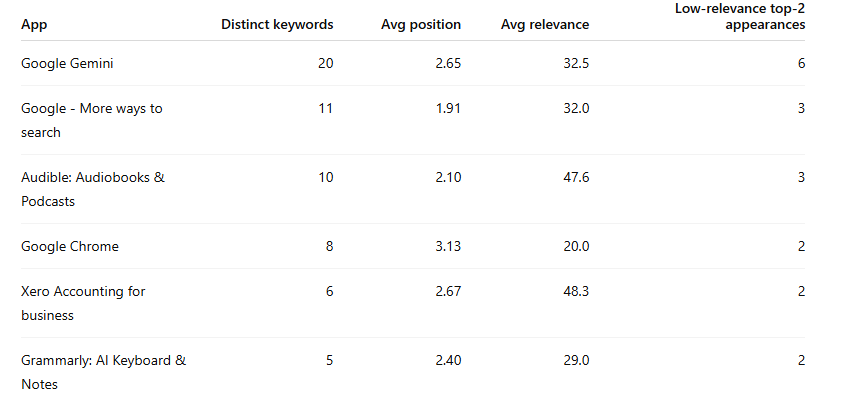
These are the advertisers most likely to be:
leaning on Search Match heavily
bidding aggressively outside core intent
using broad conquest-style acquisition tactics
Cluster 2 - Undervalued opportunity cases
These are apps that are among the best semantic matches for a keyword but still end up low in the stack.
Representative examples from the dataset:
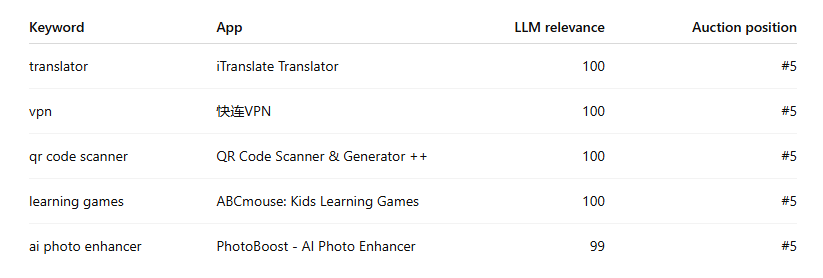
These are the keywords that should light up a campaign manager’s radar. They are often the best candidates for exact-match isolation, bid increases, or budget protection.
6. The app-level bidding strategies hidden in the data
This was one of the most interesting parts of the analysis, because once the row-level match type and bid-pressure patterns were calculated, the advertiser strategies started to look very distinct.
Apps most likely using Search Match heavily
I flagged apps with:
at least 5 distinct keywords
50%+ of appearances classified as SearchMatch

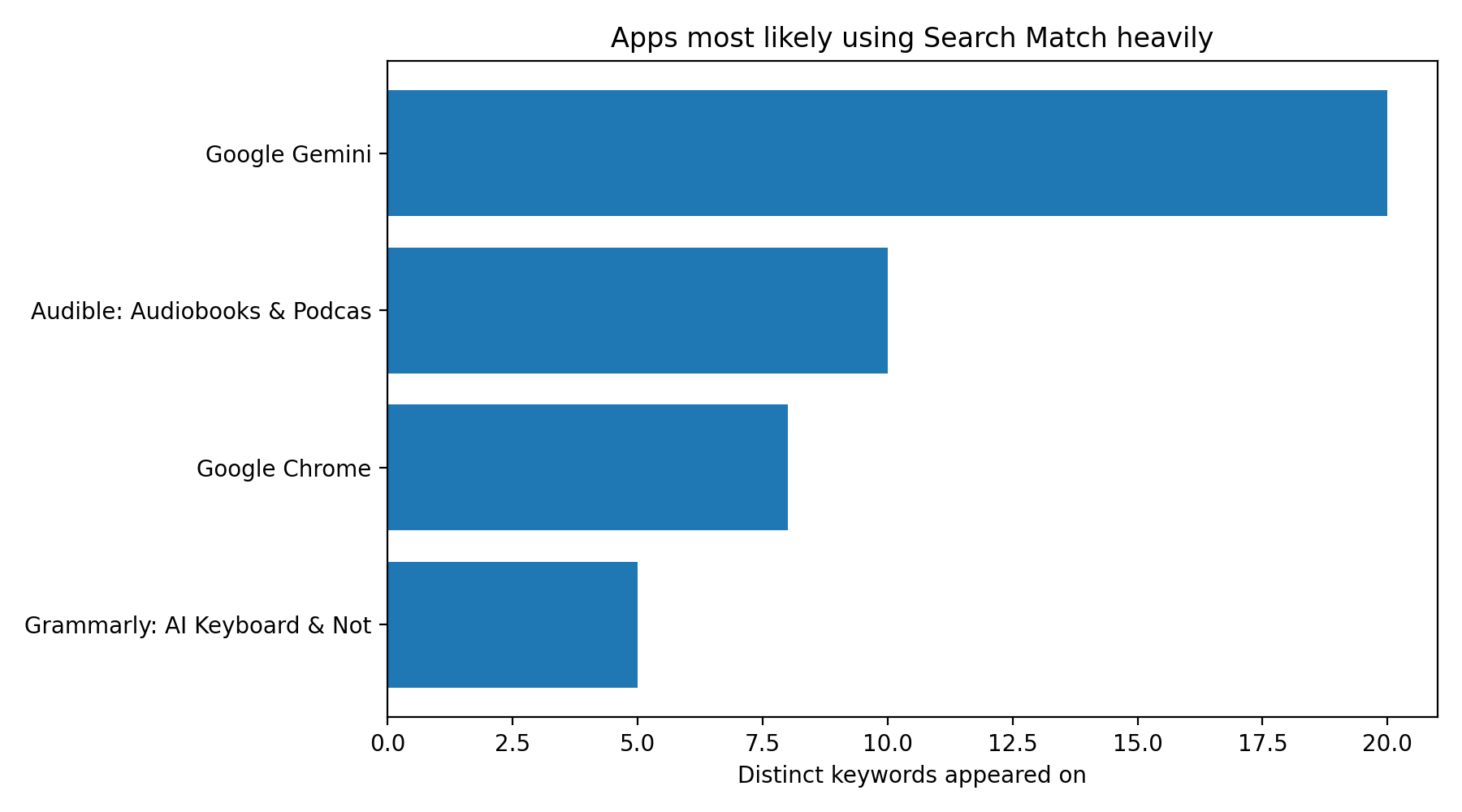
This is the clearest “strategy fingerprint” in the dataset. These apps are not simply showing for one or two adjacent keywords. They are showing across broad keyword sets with relatively weak semantic fit. That is what large-scale Search Match usage looks like.
Apps most likely running exact-heavy strategies
At the other end of the spectrum were advertisers whose appearances looked highly disciplined and semantically tight.
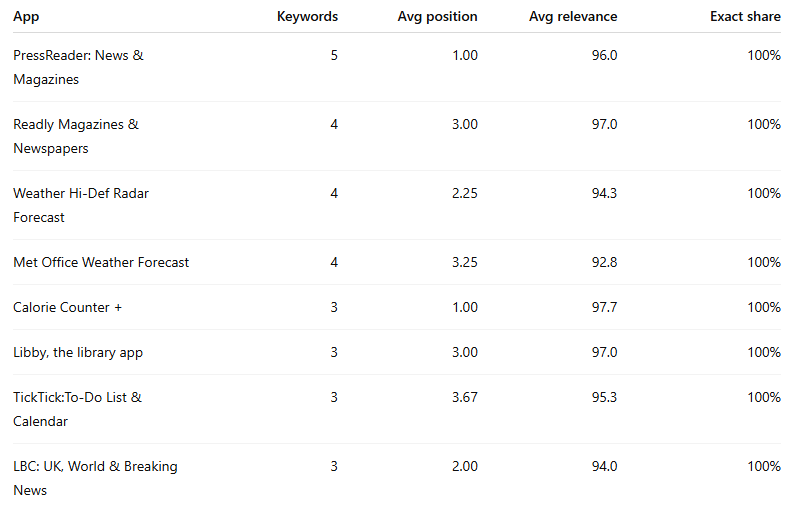
These advertisers look like they are either:
prioritising exact match,
or operating in very clean intent markets where broad/Search Match are not doing much damage.
Apps most likely running broad-heavy strategies
Apps most likely running broad-heavy strategies
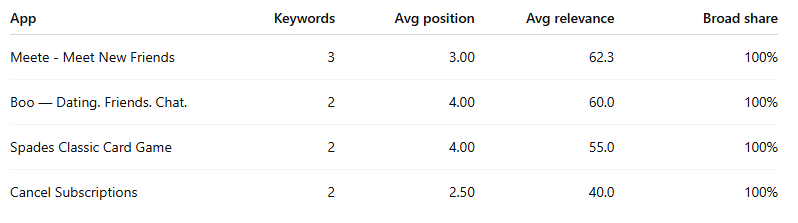
These look more like broad match exploitation of adjacent intent than full-blown Search Match drift.

7. So how does the Apple Ads auction actually work?
The strongest answer from the data is this:
Apple Search Ads behaves like a gated performance auction.
That means:
exact, broad, or Search Match generates candidates
Apple applies a relevance gate, but the threshold varies by pathway
once an app is through that gate, bid and predicted performance do most of the ordering work
That is why:
the exact relevance order matches the auction only 7.6% of the time
the top semantic app wins only 43.9% of the time
clearly weaker apps can sometimes sit at #1
clearly stronger apps can sometimes sit at #5
Apple’s own docs support the structure of that interpretation even if they do not expose the formula directly. Broad match is intentionally expansive. Search Match is a discovery system based on metadata, similar apps, and search data. Apple recommends exact for most of your efficient traffic and more moderate bidding on broad/Search Match discovery.
The dataset fills in what the docs do not say explicitly:
Relevance determines who gets through the door.
Bid and predicted engagement determine who gets the best seat in the room.
8. What campaign managers should do with this
The practical implications are significant.
If your app is highly relevant but under-positioned, that is likely a commercial problem, not a metadata problem. You can check how your app is doing using the Apple Auction Stack data in APPlyzer.
If an irrelevant or weakly relevant competitor is repeatedly outranking you, the likely explanations are:
Search Match is surfacing them
Broad match is expanding them into your query set
they are outbidding you
or Apple expects stronger engagement / conversion from them
That means the optimisation playbook should be:
isolate your best keywords into exact match
use discovery campaigns for broad and Search Match
mine the Search Terms tab relentlessly
add negative keywords aggressively
use bid pressure / relevance gap analysis to identify where you are losing auctions you should plausibly be winning
Apple’s own best-practice structure points in exactly this direction: use discovery to find terms, move winners into exact, and negate them out of the discovery campaign
9. Final conclusion
The Apple Ads auction is not random, and it is not purely pay-to-win.
But it is also not a clean semantic relevance ranking.
The best way to describe it is:
a relevance-gated, bid-and-performance-weighted auction with varying eligibility thresholds by match pathway.
That is why you see:
clean, relevance-led stacks like vpn
bizarre Search Match distortions like pdf scanner
obvious overbid / conquest cases like flight tracker
and painful missed opportunities like ai photo enhancer and translator
And that is also why the best ASA teams do not manage only by CPT and CPA. They manage by auction structure: exact versus broad versus Search Match, bid pressure versus relevance, and discovery noise versus true intent.
That is where the real edge is.
———
If you’d like to discuss how CMA can apply their award-winning knowledge to your Apple Ad Campaigns, please reach out here, or take a look at some of our amazing case studies :-)
If you’d like to take a look at this data for yourself, please don’t hesitate to visit APPlyzer and start for free!
———
FAQ: How the Apple Ads Auction Works
Is Apple Search Ads ranked purely by bid?
No. The data strongly suggests Apple uses a relevance gate before ranking ads, so not every app can win purely by paying more. But once an app clears that gate, bid and predicted performance appear to do most of the ordering work. In this dataset, the most semantically relevant app was only in position #1 around 44% of the time, which is too low for relevance to be the primary ranking factor.Does Apple rank ads by semantic relevance?
Partly, but not cleanly. Semantic relevance appears to matter most at the eligibility stage, especially for exact match. After that, the final order looks much more influenced by commercial factors like bid strength and expected tap-through or conversion performance. That is why highly relevant apps can still end up in positions #4 or #5, while weaker fits sometimes sit at #1.What is the difference between exact match, broad match, and Search Match in practice?
Exact match appears to have the strongest semantic gating, so the ads are usually tightly aligned with the keyword. Broad match seems to allow moderate semantic drift into closely related intent spaces. Search Match appears to be the loosest pathway, often pulling in apps with weak metadata relevance but plausible behavioural or category adjacency.Why do irrelevant apps sometimes appear in top Apple Ads positions?
There are two likely reasons. First, Apple’s Search Match and broad match systems can generate candidates that are only loosely connected to the keyword. Second, once those apps are in the auction, strong bids and predicted engagement can push them above more relevant competitors. That combination creates the “how is this even here?” stacks seen in keywords like “pdf scanner” and “flight tracker.”What does this mean for ASA campaign managers?
It means metadata alone does not explain auction outcomes. If your app is highly relevant but under-positioned, the problem is usually commercial rather than semantic. The right response is often to isolate the keyword into exact match, review Search Terms, tighten negatives, and reassess bids rather than assuming the store listing itself is the main issue.How should Search Match be used?
As a discovery tool, not as a core efficiency engine. Search Match is useful for uncovering new queries and adjacent intent spaces, but the data suggests it can also introduce significant noise. The safest structure is to run Search Match separately, mine it for good queries, move winners into exact match, and negate wasted traffic back out of discovery campaigns.What is bid pressure in Apple Search Ads?
Bid pressure is a practical way of describing when an app is winning a higher auction position than its semantic relevance would imply. In this article, it is estimated by comparing an app’s relevance rank for a keyword with its actual auction position. Positive bid pressure often signals conquesting, aggressive Search Match budgets, or broader acquisition tactics.How can you spot under-bidding or missed opportunities?
Look for cases where an app is one of the most semantically relevant results for a keyword but still sits low in the auction stack. Those are usually the best opportunities for exact-match isolation, bid increases, and budget protection. In this dataset, terms like “translator,” “vpn,” and “ai photo enhancer” showed clear examples of that pattern.What is the simplest takeaway from this analysis?
Apple Search Ads looks best described as a relevance-gated, bid-and-performance-weighted auction. Relevance decides who gets through the door. Bid strength and expected engagement decide who gets the best seat in the room.
If you like this article, we’d love to speak to you about how we might be able to help, so please do reach out here, or take a look at some of our amazing case studies :-)


